Problem
We had an issue with MRP running really slow(3 consecutive runs), and we were asked to reboot our app server which we did and haven’t seen slow MRP for the past couple days. We were then asked if we periodically reboot our app server and if not if we could start.
Rationale
My experience is with Linux, where periodic reboots are considered a bad idea. The consensus seems to be if you have a problem, try to understand and address the root of the problem vs rebooting just in case. So I was not in agreement to reboot periodically unless we had a good reason(I wouldn’t consider MRP a good reason as we don’t know the reboot is what “fixed” the problem as we don’t have enough data or understanding). In speaking with someone more experienced and knowledgeable than I with Epicor servers, they agreed monthly reboots are a good idea… So I’ll yield to someone more experienced and knowledgeable than myself and am looking to get this setup.
Questions
Should we be rebooting both DB and App server?
If so does order of reboot matter(I’d think DB then App server)?
Our webstore will be offline during the reboot, an recommendations in this regard?
For the period, is monthly reasonable?
Any experience anyone can share on this topics(dos/don’ts)?
PS Ownership isn’t onboard with the idea of keeping Epicor relatively current, so we have no plans to upgrade. They fear the costs and unknown risks associated an upgrade(we’ve only upgraded once so lack experience and have heavily customized Epicor).
App Servers should work without a reboot. I dont reboot anything regularly to get it to work, it just works. Sometimes I dont reboot for 6 months especially TEST which sits in an isolated domain and isnt patched like Production, it is a mirror of Production with all schedules running and ocassionaly data is refreshed.
IIS recycles itself, that is good enough. If MRP causes bottlenecks for running too long, that sounds like an Epicor Bug.
–
Also Note: We run a 24/7 high paced environment, where we run with 0 downtime, and have multiple app-servers. Perhaps im not the best to give advice for someone who may not have resources.
TL;DR:
Nothing should ever get rebooted for a performance gain, it should just work, its a server. Linux is a prime example, uptime of a decade, still 0 slowness.
In a Windows environment, the need for a reboot is usually due to a memory leak. Although Windows is a LOT better at this than it used to be, it still happens, and any process or program can be a culprit.
We do reboot once a month (all the servers, db first then app and task) but its not for performance issues, its because windows updates require a reboot. The problem with saying its a bug that is causing the MRP issue is that 10.2.400 is out of active support, so even if it is a bug, Epicor will not do anything about it except tell you to upgrade to a later release.
Also meant to say re: downtime, your webstore runs directly on your Epicor server? We use a replicated database so rebooting our Epicor servers doesn’t take anything else down, it just doesn’t update for a few minutes.
You may want to segregate your websites from ERP. I mean, you are asking to be hacked, the easiest way into a network is always through the website former contributor to c99shell here started on IRC on dalnet.
No not on the same box, I wouldn’t want ERP server on the internet Our webstore uses API calls to pull data in, create orders, etc. But if Epicor is down, then our webstore API calls will fail. I believe it says something like Under Maintenance when this happens.
Why? rebooting has quite a bit of downside when it comes to performance at least from a SQL standpoint.
You force a clean cold cache of data, clean cache of query plans, all internal caches are cleared, all your memory loaded data from the disks is wiped, it kills statistics. Rebooting your server should be a last resort IMO
Similarly applies to IIS btw, it has to cold start your entire Epicor app server, there is even a “pre-heater” that Epicor makes available specifically because starting up the Epicor app is such a slow painful process.
If you are having to do this, something else is broken.
1 and 2. Theoretically, you should be able to just reboot your App server, since that is where the problem is. However, you may discover that it’s best (in your environment) to do both. If that is the case, then make sure the DB server comes back up before the App server goes looking for it.
3. If the time your webstore is “under maintenance” while this is going on is not acceptable to whoever gets to make that call, then you’ll have to do something about it. Otherwise, let it slide.
4. This is an imperfect solution, so “the period” should be whatever you can get away with doing. If monthly works, great. If you have to do it weekly, then monthly won’t work.
5. The MRP Process does a lot of stuff in a black box that we can’t see. If that is where the underlying issue is, and the only thing that will fix it is an upgrade, AND you’re forbidden to upgrade, then you’re stuck here. It is also possible (I have no idea how likely) that there is bad data somewhere, perhaps in a MOM, causing the problem You might want to turn on logging for “MRP and Scheduling”, and the first time you notice a slowdown, look through the logs for which part number(s) are taking longer than normal to process. This is manifestly NOT a fun task.
Well probably. (At that time I was not involved in this… ) The origin of this daily reboot I was told it was due to some memory leak and IIS . I guess doing it differently was never thought about or challenged…
The app server and DB is on same physical machine (currently) .
We will eventually seperate when we will upgrade to Kinetic.
We were on 10.2.400 when I started here and had periodic issues that could seemingly only be resolved with a reboot. After some investigation, I found that app pool recycling had not been configured on the server. Once I set my ERP app pool to recycle every day at 3 a.m. the system got much more stable.
@josecgomez or @hkeric.wci would love to hear your perspective on periodically recycling the app pool(ok / bad idea? how often if ok? any other tips?). You and Haso convinced me the reboot is a bad idea… Our app pool is setup to recycle once a week. I understand this will kill our cache / hurt performance, and it sounds like we should be using a preheater or a script with curl calls to relevant APIs, assuming you think this is a reasonable practice(schedule app pool to recycle once a week)… Where can we get the preheater or does anyone have an example script?
FYI We have separate servers(esxi VMs) for our DB and App server. We have 15 default licenses(typically 8-10 users active), and 7 data collection licenses (typically 3-5 users active).
No I do not think that recycling weekly is a “reasonable practice” like every software you should only recycle Epicor if it needs it.
The pre-heater is built in to the PDT
The documentation is not really great… but you can run PreHeaterCmd.exe --help and see what it expects. I’ve messed with it a bit but it hasn’t been worth it. We try and keep the recycling to a minimum.
But it wouldn’t be hard to implement one in Postman using REST particularly in 2021+ just have Postman do a series of REST calls to the most used BOs.
It can be confusing as I hear so many conflicting recommendations as to what best practices are. You and @hkeric.wci really seem to know the Epicor stuff well and I can’t thank you guys enough for all the help over the years! I’m going to disable that weekly recycle as it sounds like we know it will actually hurt performance(caching). If we have problems then we’ll focus on understanding and fixing the root of the problem, and not using Band-Aid workarounds like magic reboots.
@josecgomez given your recommendation we have stopped periodically recycling the IIS pool once a week, once we realized we were likely hurting performance by killing our cache - thanks for that!.
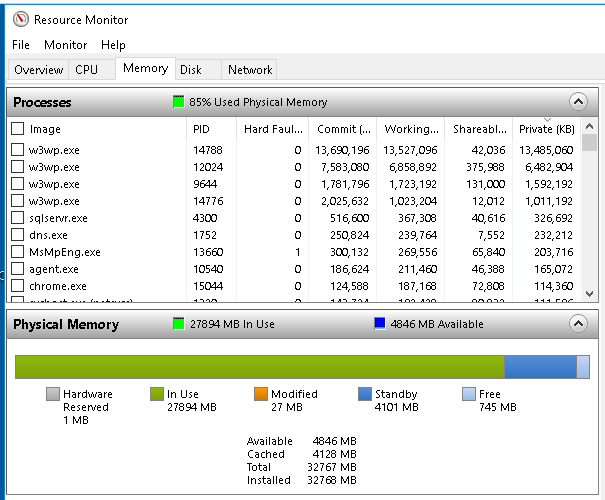
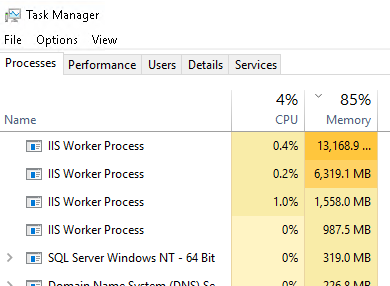
We just noticed RAM on the app server is at 85% utilization, primarily utilized by IIS. This is the reason I believe we thought we needed to recycle the IIS pool previously(assumed a memory leak)… Is this problematic(our MSP brought it to our attention), and if so any recommendations?
I’m not sure what additional information would be helpful beyond we’re a small company with about 10 Epicor users. At the time of this screen shot we had 6 default users, 1 web service user, and 4 MES user’s connected.
@josecgomez I’m not great at patching Windows, but can’t imagine we’re more than a month out of date(will patch tonight).
In terms of patching Epicor, well that’s a tough one. We’re on 10.2.400.5. I’m googling around now to try to see if there is a newer 10.2.400.x version available. Having said that our last upgrade was from version 9 to 10, and the amount of work, customization & reports that needed ported, and resulting problems I think scared ownership and we’ve talked about upgrades quite a bit(can’t get phone support anymore) and they don’t want more upgrades at this time…
Is there by chance a changelog or anywhere we could know a memory leak was fixed, vs upgrading an hoping there was one and the upgrade will fix it?
The current version is 10.2.400.40 (of your release find release notes attached) includes all things fixed in all prior versions ReleaseNotes.pdf (490.6 KB)
As far as upgrading goes a jump to 10.2.700 should be fairly un-eventful and would get you much closer to current.