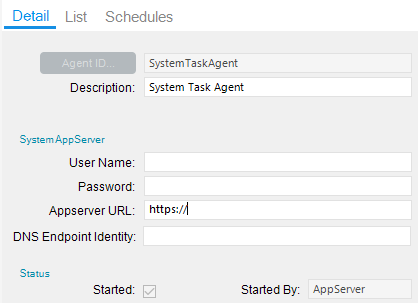
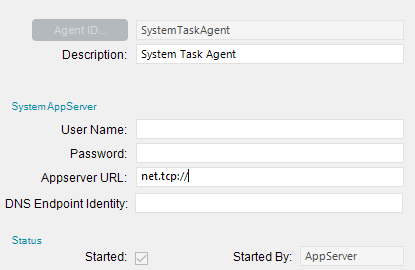
If this continues to happen investigate if you need to increase the receive and send timeouts in your web.config.
Error details:
System.ServiceModel.CommunicationException: The socket connection was aborted. This could be caused by an error processing your message or a receive timeout being exceeded by the remote host, or an underlying network resource issue. Local socket timeout was ‘1.00:00:00’. —> System.IO.IOException: The read operation failed, see inner exception. —> System.ServiceModel.CommunicationException: The socket connection was aborted. This could be caused by an error processing your message or a receive timeout being exceeded by the remote host, or an underlying network resource issue. Local socket timeout was ‘1.00:00:00’. —> System.Net.Sockets.SocketException: An existing connection was forcibly closed by the remote host
at System.Net.Sockets.Socket.Receive(Byte buffer, Int32 offset, Int32 size, SocketFlags socketFlags)
at System.ServiceModel.Channels.SocketConnection.ReadCore(Byte buffer, Int32 offset, Int32 size, TimeSpan timeout, Boolean closing)
— End of inner exception stack trace —
at System.ServiceModel.Channels.SocketConnection.ReadCore(Byte buffer, Int32 offset, Int32 size, TimeSpan timeout, Boolean closing)
at System.ServiceModel.Channels.SocketConnection.Read(Byte buffer, Int32 offset, Int32 size, TimeSpan timeout)
at System.ServiceModel.Channels.DelegatingConnection.Read(Byte buffer, Int32 offset, Int32 size, TimeSpan timeout)
at System.ServiceModel.Channels.ConnectionStream.Read(Byte buffer, Int32 offset, Int32 count)
at System.Net.FixedSizeReader.ReadPacket(Byte buffer, Int32 offset, Int32 count)
at System.Net.Security.NegotiateStream.StartFrameHeader(Byte buffer, Int32 offset, Int32 count, AsyncProtocolRequest asyncRequest)
at System.Net.Security.NegotiateStream.ProcessRead(Byte buffer, Int32 offset, Int32 count, AsyncProtocolRequest asyncRequest)
— End of inner exception stack trace —
at System.Net.Security.NegotiateStream.ProcessRead(Byte buffer, Int32 offset, Int32 count, AsyncProtocolRequest asyncRequest)
at System.Net.Security.NegotiateStream.Read(Byte buffer, Int32 offset, Int32 count)
at System.ServiceModel.Channels.StreamConnection.Read(Byte buffer, Int32 offset, Int32 size, TimeSpan timeout)
— End of inner exception stack trace —
Server stack trace:
at System.ServiceModel.Channels.StreamConnection.Read(Byte buffer, Int32 offset, Int32 size, TimeSpan timeout)
at System.ServiceModel.Channels.SessionConnectionReader.Receive(TimeSpan timeout)
at System.ServiceModel.Channels.SynchronizedMessageSource.Receive(TimeSpan timeout)
at System.ServiceModel.Channels.TransportDuplexSessionChannel.Receive(TimeSpan timeout)
at System.ServiceModel.Channels.TransportDuplexSessionChannel.TryReceive(TimeSpan timeout, Message& message)
at System.ServiceModel.Channels.SecurityChannelFactory`1.SecurityDuplexChannel.TryReceive(TimeSpan timeout, Message& message)
at System.ServiceModel.Dispatcher.DuplexChannelBinder.Request(Message message, TimeSpan timeout)
at System.ServiceModel.Channels.ServiceChannel.Call(String action, Boolean oneway, ProxyOperationRuntime operation, Object ins, Object outs, TimeSpan timeout)
at System.ServiceModel.Channels.ServiceChannelProxy.InvokeService(IMethodCallMessage methodCall, ProxyOperationRuntime operation)
at System.ServiceModel.Channels.ServiceChannelProxy.Invoke(IMessage message)
Exception rethrown at [0]:
at System.Runtime.Remoting.Proxies.RealProxy.HandleReturnMessage(IMessage reqMsg, IMessage retMsg)
at System.Runtime.Remoting.Proxies.RealProxy.PrivateInvoke(MessageData& msgData, Int32 type)
at Ice.Contracts.RunTaskSvcContract.RunTask(Int64 ipTaskNum)
at Ice.Proxy.Lib.RunTaskImpl.RunTask(Int64 ipTaskNum) in C:_Releases\ICE\UD10.2.500.5FW\Source\Shared\Contracts\Lib\RunTask\RunTaskImpl.cs:line 147
at Ice.TaskAgentCore.ServiceCaller.<>c__DisplayClass34_0.<RunTask_RunTask>b__0(RunTaskImpl impl)
at Ice.TaskAgentCore.ImplCaller.RunTaskImplCaller1.<>c__DisplayClass4_0.<Call>b__0(TImpl impl) at Ice.TaskAgentCore.ImplCaller.RunTaskImplCaller1.Call[TResult](Func2 doWork, ExceptionBehavior communicationExceptionBehavior, ExceptionBehavior timeoutExceptionBehavior) at Ice.TaskAgentCore.ImplCaller.RunTaskImplCaller1.Call(Action`1 doWork, ExceptionBehavior communicationExceptionBehavior, ExceptionBehavior timeoutExceptionBehavior)
at Ice.TaskAgentCore.ServiceCaller.RunTask_RunTask(Int64 sysTaskNum, ExceptionBehavior communicationExceptionBehavior, ExceptionBehavior timeoutExceptionBehavior)
at Ice.TaskAgentCore.ScheduleProcessor.CallServiceAction(SysTaskRow sysTaskRecord, SysTaskParamRow companyParamRecord, ServiceCallArguments serviceCallArguments)