We seem to have something going on with our transaction log backups…we have our backup plans to do do a full backup every Sunday night, differentials every night and transaction log backups every 15 minutes between 6am and 6pm.
This mornings (Monday) 6am transaction log backup was 13Gb!! This along with a 50Gb logfile filled the disk so the log backup failed and the alerts started rolling in. Typically the 6am log backup is about 300Mb.
What could cause such a blow out in the transaction log backup?
Note: We just patched from 10.2.100.24 to 10.2.100.37 on Saturday evening so that might be related but all that activity should be covered in Sundays backups.
From what ive been told, transaction log backups include everything since the last Diff backup. Not sure if a more recent Full backup resets that.
Any reason you don’t do Diff backups everyday?
Edit
And since your last Diff was before an upgrade, the TransLog backup might be including everything the update did. Theoretically you could “un-update” the DB
Full backups don’t reset the log chain. The log will continue to grow if only full backups are taken. Differentials are “all changes since the last full backup” and transactions are “all changes since the last transaction backup”.
Does your full backup on Sunday include rebuilding indexes or anything like that? If it had to do a lot of that after the upgrade, that might be what the t-log backup captured.
Wow! You’d need a lot of space for that! It really depends on how much storage space you have available, how long you want to keep backups, how much activity your database sees, how much data you can afford to lose, and how much downtime you can tolerate while they restore. We do a nightly full backup and hourly t-logs. We risk losing an hour of data, but it keeps our backups within limits and allows quick restores.
The restore time of a differential from day 6 might be worse than one day’s worth of transactions.
That’s only assuming you keep all the old backups. No need to keep the Tran Log backups after you’ve made a new Diff backup. Same thing for Diff’s older than the lates Full backup.
What’s the size comparison of a Diffs + all the Tran Logs since that Diff? Bigger than a Full?
Not so, if you want to be able to restore to a point in time. You may not discover a problem until much later. I do clear out old trn backups sooner than old fulls, but I keep a few weeks’ worth.
I think that depends on how much activity the database sees. If you effectively replaced all the data in a week, the diff would be massive. Brett’s is about 40% of the full in that screenshot. It’s a balance between size and restore time. Full disclosure, I’ve never tried restoring a differential.
I’ve done this, actually–I’ve restored from the moment before a job got closed or Capture COS/WIP was run, to Test, in order to trace why something happened.
So what’s the size difference between a differential backup and the transaction logs that cover the same time period?
Yes there is a scheduled rebuild of indexes on the 1st of the month at 2am so that explains the large transaction log. So I guess we should expect a very large transaction log backup on the 1st of every month then…I wonder if we can (or if it makes sense) to exclude the indexes from the back…I guess that would make restore times longer as we would have to build them after a restore event…
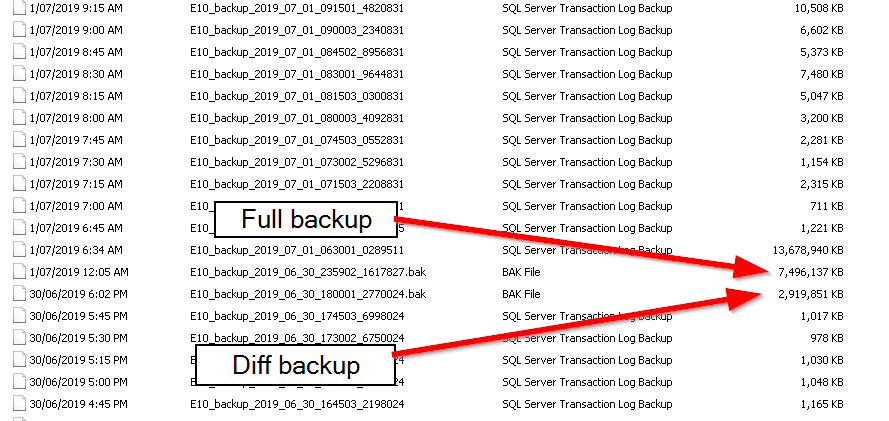
The transaction log backups are about 1Mb for 15 minutes when no one is using the system and then usually 5-10 Mb with spikes to 50Mb when the system is in use. The first tran log backup of the morning (which covers from 6pm to 6am is usually 200 - 300 Mb. The weekly full backup is running at 7.2Gb and the diff gets up to 2.9Gb.
Between the last 2 full backups it has grown by 200Mb - seems reasonable. While the Diff over the same time was 2.9Gb which seems excessive. To me this says we are not creating a many new records but we are updating LOTS of records. I wonder if we have some runaway process somewhere…
You might want to take a cursory view of your Disk Usage by table report in SQL server and see if that gives you any clues.
With regards to the monthly reindex. It might be worthwhile to run a full backup after the reindex as a second step and if the reindex fails the skip the backup. Or as mentioned here do the reindex before the full backup
I have been keeping an eye on the top tables. The ABT tables are big (~ 6.5Gb) and i understand i need to create a ticket with Epicor to get a data fix for that. The other stand out is the large indexs for TranGLC and GLjrnDtl. I have created a few indexes using the SQL performance tuning advisor when BAQ’s run too slow but the majority of the space is taken by std Epicor indexes. I think i need to address our lack of data purging. We have never done a purge on the database or even have a policy on when / how we will purge…
In terms of the large transaction log backup, i guess i just have to accommodate the file size if i want to keep the log chain intact…
Is the recommendation to do a index rebuild right before an full backup is so that you reduce the chances of needing that massive transaction log backup file in a restore operation?