I’m definitely not a SQL Index expert so please forgive me if I am totally wrong here but…I personally feel like Epicor needs to take a look at and revamp their Indexes on the Tables that are used in the MRP process. I believe there are WAAAY too many indexes and WAAAY too many fields on each index. (Even Brent Ozar, a SQL database expert, recommends no more than 5 Indexes on a Table and no more than 5 Fields on an Index. Of course I understand there are cases where you might need more but if you look at what Epicor has, it seems like total overkill. Too many of either can actually slow processes down.) Whenever there is an Insert, Update, or Delete of some data in a table then ALL of the Indexes on that table that contain the data have to be updated. SQL Server will lock (depending on locking level) the table and ALL of the Indexes involved until the data transaction\modification is complete. If a table contains a lot of Indexes with a lot of Fields that need to be updated for every transaction and multi-threaded processes try touching these tables all at the same time, it could cause a lot of Blocking and waiting (which could slow the MRP process down considerably) and it could also cause Deadlocks.
I believe that’s why there is so much “hoo-doo voo-doo” when trying to choose the right amount of Processors and Schedulers to use when running MRP. If you use TOO MANY processors it can actually SLOW DOWN MRP. It’s because one processor takes a looong time to update ALL of the Indexes that it has to touch on a table and there are other processors out there that want to grab up that same resource that is already in use by the first processor. Those other processors can’t grab a hold of that resource until the first one that grabbed it is finished with it so they have to sit and wait and keep checking back to see when the resource is released and they can start using it. So multi-threaded processors end up getting blocked and having to wait until the original processor that is locking the resource is finished with it. So if there are far too many indexes and fields that need to be updated each and every time an Insert, Update and Delete happens, and there is a lot of Blocking of Processors because of that, then it will take a long time for the entire (MRP) process to finish. So Epicor tells you to play with the Processor and Scheduler numbers until you find that “sweet-spot” where the amount of processors that run aren’t all competing with each other and asking for the same resources at the same time and waiting on each other to finish updating all of the indexes out there.
This is something I posted out on Epicor Ideas site (if anyone agrees with my findings please vote! I truly think that Index Tuning of the MRP tables would help to speed up MRP.):
Speed Up MRP - Consider Expert Index-Tuning of the Epicor Indexes on Tables
I wonder if a slow MRP process (especially when using more threads) is caused by:
- Too Many Indexes on One Table
- Too Many Fields in One Index
-
Locking and Blocking (could be the reason why fewer threads are a lot faster)
Too Many Indexes on One Table: If you look at Epicor’s indexes there are, what seems like, “a lot” of Non-Clustered Indexes on one single table. The more non-clustered indexes you have on a table, the slower your inserts, updates and deletes will go. If you have a table with 10 non-clustered indexes, that’s 10x (or more) writes an insert has to do for all of the data pages involved with each index. (Courtesy Brent Ozar)
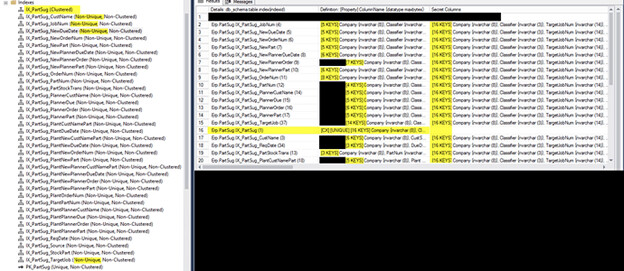
For the PartSug Table (this one causes us problems when we run MRP) there are 36 Indexes (35NC + 1CX):


Can that be considered “a lot”? Brent Ozar has a 5 and 5 rule/suggestion (of course there are exceptions) but he usually recommends 5 indexes on a table and 5 columns per index.
Too Many Fields in One Index: The more columns you add to an index, the “heavier” (GB a page takes up and row count) that index gets. This is particularly important if writing to the table happens. The more indexes I add, the more work my writes have to do. The more columns are in each index, the more that gets magnified.
I hope I understand this correctly but for the PartSug Table all of the Non-Clustered Indexes are Non-Unique which means that SQL Server will add all of the columns from the Clustering Key to the NC Index to make it unique. For this example, the Clustering Key of the Table includes all 16 Columns of the Clustered Index. All 16 of those columns are added to EACH NC Index (duplicates are removed if they are in the NC Index Keys) which means that each of the 35 NC Indexes have at least all 16 Clustered Index Columns in them. And any time any of these 16 Columns need to be changed or a new record added or deleted ALL of the NC Indexes need to be touched.
Locking Blocks: Locking and blocking is a normal and required activity in SQL Server. It happens when two processes (threads) need access to same piece of data concurrently so one process locks the data and the other one needs to wait for the first one to complete and release the lock. As soon as the first process is complete, the blocked process resumes operation. The blocking chain is like a queue: once the blocking process is complete, the next process can continue. In a normal server environment, infrequent blocking locks are acceptable. However, if we execute long, complex transactions that read lots of data, and take a long time to execute, then locks will be held for extended periods, and blocking can become a problem. When blocking occurs for extended time periods, it can impact the performance of many user processes. With blocking, however severe, no error is raised.
DeadLocks: (We are currently experience several Deadlocks on our PartSug table each time we run MRP.) Occurs when one process is blocked and waiting for a second process to complete its work and release locks, while the second process at the same time is blocked and waiting for the first process to release the lock. In a deadlock situation, the processes are already blocking each other so there needs to be an external intervention to resolve the deadlock. For that reason, SQL Server has a deadlock detection and resolution mechanism where one process needs to be chosen as the “deadlock victim” and killed so that the other process can continue working. The victim process receives a very specific error message indicating that it was chosen as a deadlock victim and therefore the process can be restarted.
I just wonder if Too many Indexes on one Table, Too many Fields on one Index and Locking and Blocking are what is slowing MRP down, especially when you have more than a few threads running at one time. In the PartSug example above, if a large number of threads are used to run MRP it could potentially mean that they are all trying to make changes to the 35 NC Indexes at one time. (And this is just ONE Table that I’m looking at!) And if you lower the amount of threads that MRP is running it doesn’t run into as many Locking and Blocking issues and it will run a lot faster. Just a theory of mine. Thanks!


