I have a Dashboard where the lines rarely occur twice, but if they do the user should know about it. Therefore, I need the dashboard to be able to highlight duplicate fields. I cannot figure out how to set the filter values in the dashboard to create this highlight.
The dashboard I have is for sales order lines with the bin location of the part. I have already added filters in the BAQ to only show bins in the preferred warehouse. however, there is a rare occasion where the parts are briefly kept in two different bins (because of physical size of the part, i.e. they are too big and cannot fit into one bin). In this case, my Dashboard shows two bin locations for the same order line. I want the dashboard to highlight these duplicate occurring lines.
Conceptually, what I envision is some sort of “second pass” over the original dataset. You might be able to accomplish this by using a subquery as your first pull of data encapsulated by a top level query. In the top level query, you would have the subquery results available and could perform a calculated field of each of the results, i.e. you could use a count + partition by over rows. If the count is greater than 1, you could set a highligher on that row.
Also, Don’t know what it would do to performance. But if you make every field of the the top level of the BAQ as ‘Group By’, you’d never get any repeats
This is only if you just don’t want to see them. If you need to find them to take some action then, this ain’t for you.
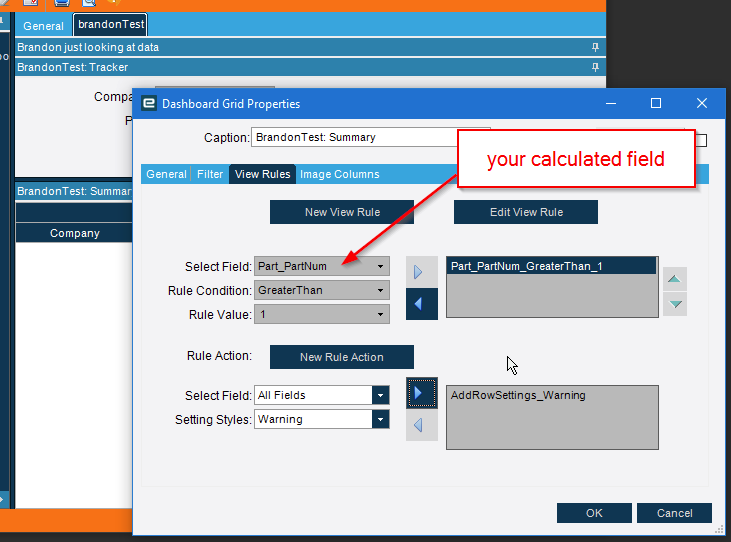
If you a calculated field that is simply 1, then do a
sum(calculated field) over (partition by x)
(syntax might be wrong, but you get the point)
with x probably being another calculated field where you concatenate the order number, line, the sum for those lines would be NOT 1. So you could add your row condition for <> 1.
This is one thread where they talk about this feature.
This is almost what @Aaron_Moreng said, except I don’t think you need a sub query.
The same thing could be accomplished with sub queuries instead.