This is a very detailed drawing of a dashboard I am working on right now. The arrows represent parameters I am passing between queries. Everything seems to work great except when some queries do not return data.
Per this post Dashboard not refreshing 2nd query I have found that my issue lies in the fact that when a query does not return data, it does not have a selected row, and therefore does not notify any queries that subscribe to it’s data that they should now take blank inputs.
Any ideas on how to best refresh some queries based off which query goes blank? My initial thought was an AfterRowChange method in a UI customization, but that seems to get called multiple times per row change, so multiple refreshes per row change could take a lot of time.
I’ve had other experience, where if a publishing query doesn’t return a row, it runs the subscribing dashboard wide open, which can lock up the UI while it waits for the query to return.
I do no know of a way to run a subscribing query if no row returns in dashboard land. I believe you would have to make your own from scratch. (like use a emptied out UD screen and add your own stuff)… But yuck!
This row only populates the first two queries, but the third query does not update what it is publishing so the side query and bottom two queries still show the data from the previous row.
This is something I thought of as well, I’m just not sure how to get it to work. Would the dummy row then show even if the query returned results? (Because that would not be ideal)
Follow up question, where am I putting this filter. I’m not seeing a way to do the Max filter in the dashboard. (Or at least when I tried doing Calc_SortLevel = Max(Calc_SortLevel) it didn’t work)
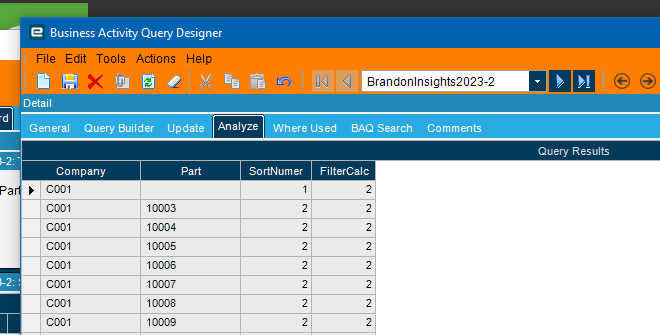
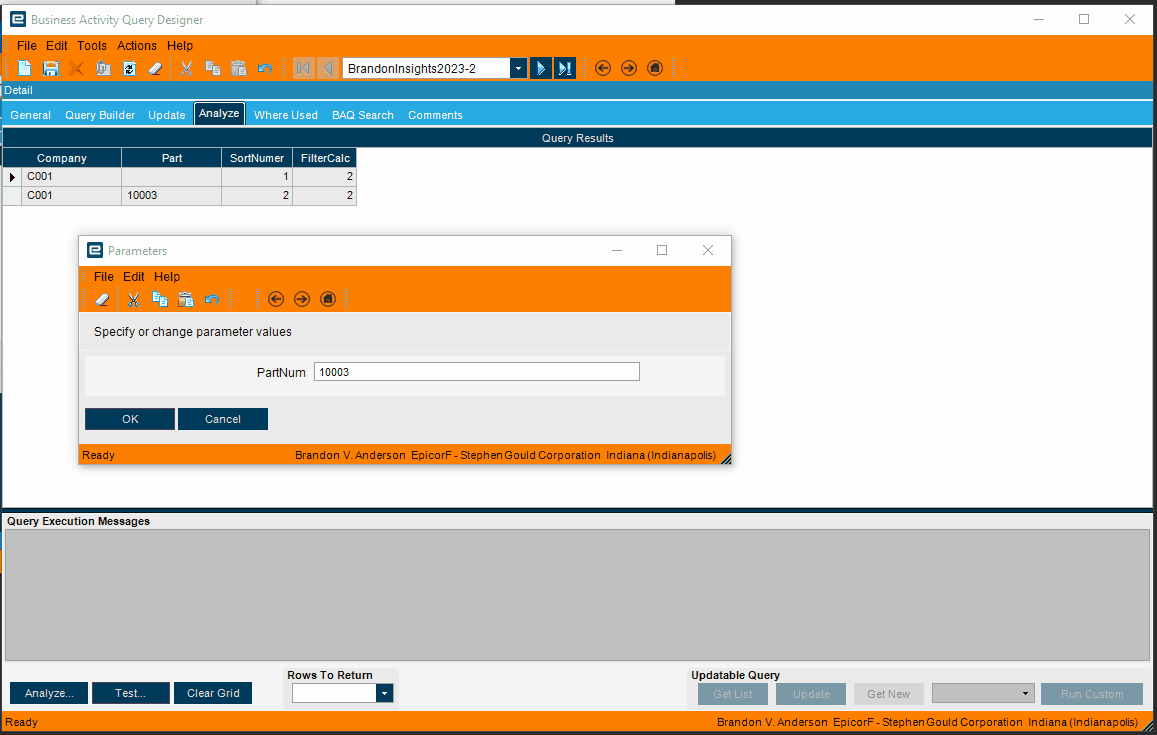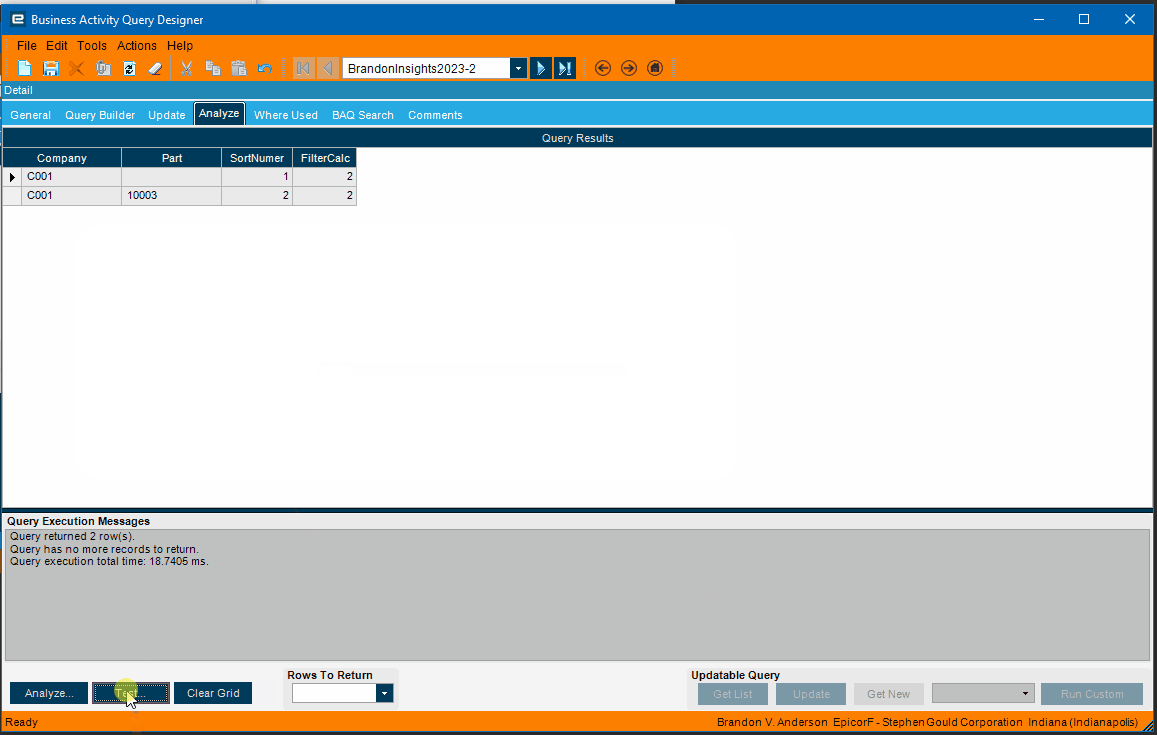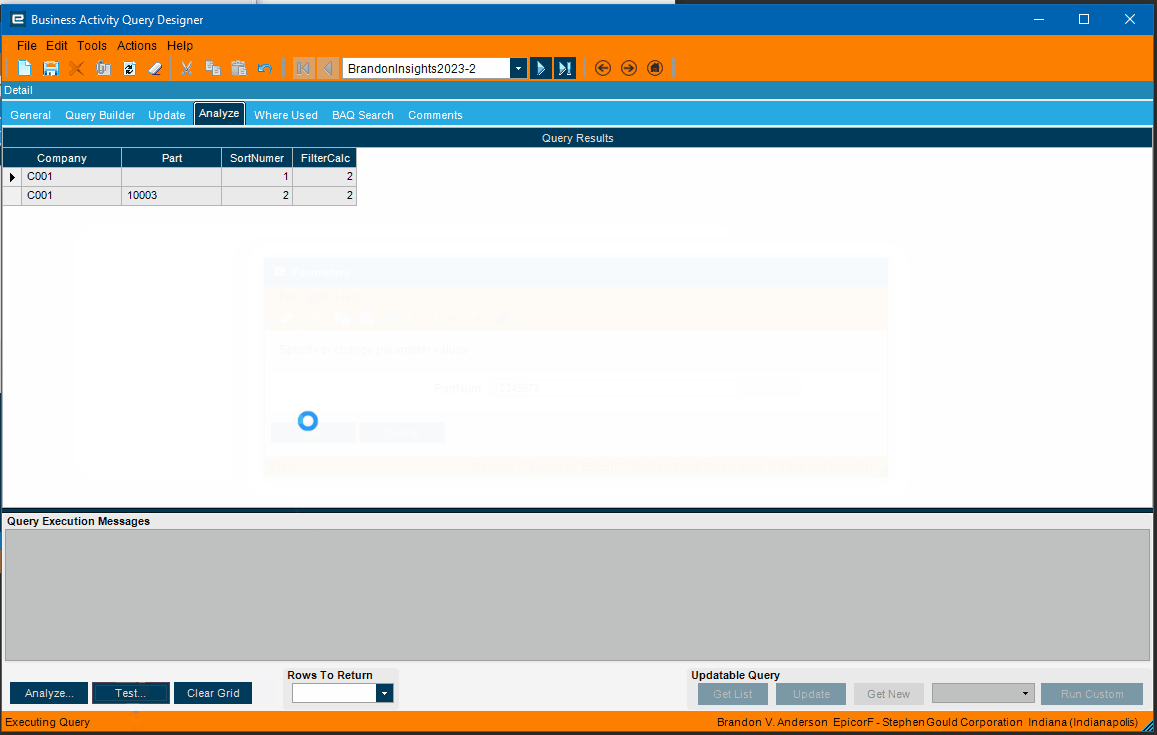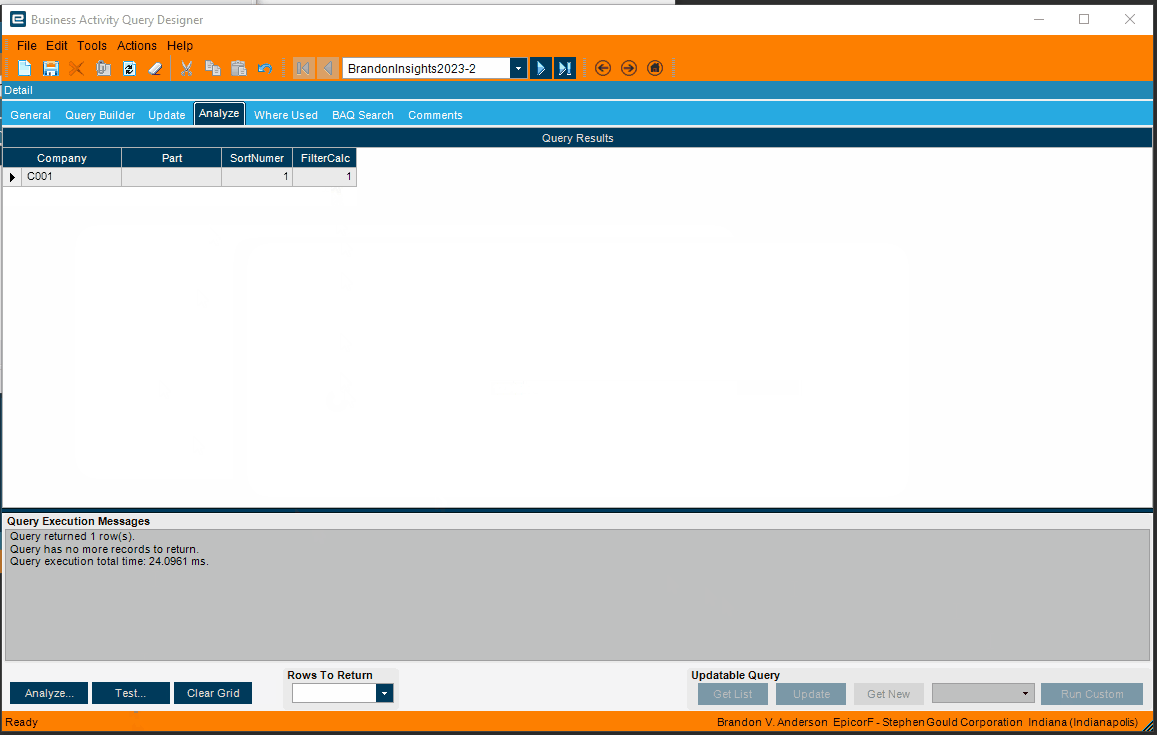
Here’s the rows that it would return with no filter.
This is adding a filter for SortNumber = FilterCalc
Are the queries that are returning empty sets subscribing queries? If they are you can set the filter on the dashboard to a parameter, and I believe that this should work.
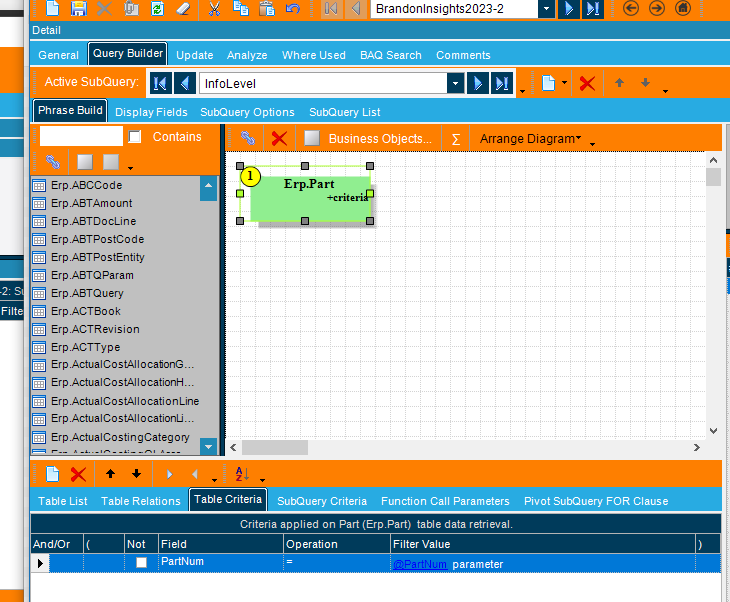
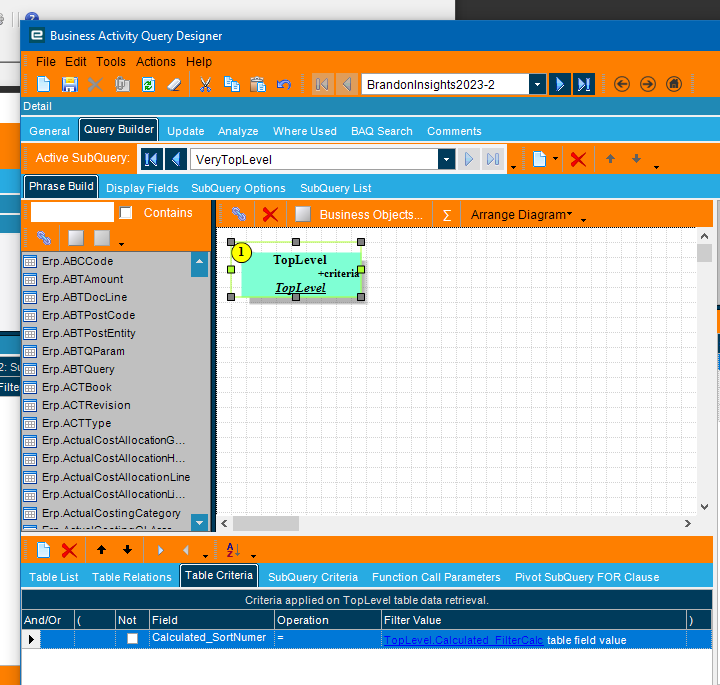
Here’s the BAQ if you want to see what I did. Change the company dummy field to your company or whatever field you want to add in there to do your partition.
/*
* Disclaimer!!!
* This is not a real query being executed, but a simplified version for general vision.
* Executing it with any other tool may produce a different result.
*/
select
[TopLevel].[Part_Company] as [Part_Company],
[TopLevel].[Part_PartNum] as [Part_PartNum],
[TopLevel].[Calculated_SortNumer] as [Calculated_SortNumer],
[TopLevel].[Calculated_FilterCalc] as [Calculated_FilterCalc]
from (select
[InfoLevel].[Part_Company] as [Part_Company],
[InfoLevel].[Part_PartNum] as [Part_PartNum],
[InfoLevel].[Calculated_SortNumer] as [Calculated_SortNumer],
(max(InfoLevel.Calculated_SortNumer) over (partition by InfoLevel.Part_Company)) as [Calculated_FilterCalc]
from (select
[Part].[Company] as [Part_Company],
[Part].[PartNum] as [Part_PartNum],
(2) as [Calculated_SortNumer]
from Erp.Part as Part
where (Part.PartNum = @PartNum)
union
select
('C001') as [Calculated_CompanyFill],
('') as [Calculated_PartNumFill],
(1) as [Calculated_SortNumber]) as InfoLevel) as TopLevel
where (TopLevel.Calculated_SortNumer = TopLevel.Calculated_FilterCalc)
I tell you what I will definitely be coming back to this a lot, this is a very different way than I have looked at BAQs in the past, but it works and seems very useful. I appreciate the walkthrough.
Note: I make not guarantees on if this is efficient or not. It just lets me do it… So take it with a grain of salt. I haven’t done any analysis if this is a crappy way to do it. It could be (probably is) much more efficient to run your query, then on post processing get list, count the rows, and if 0 then add a blank row. But if you don’t want to mess with that, this is a way to do it.