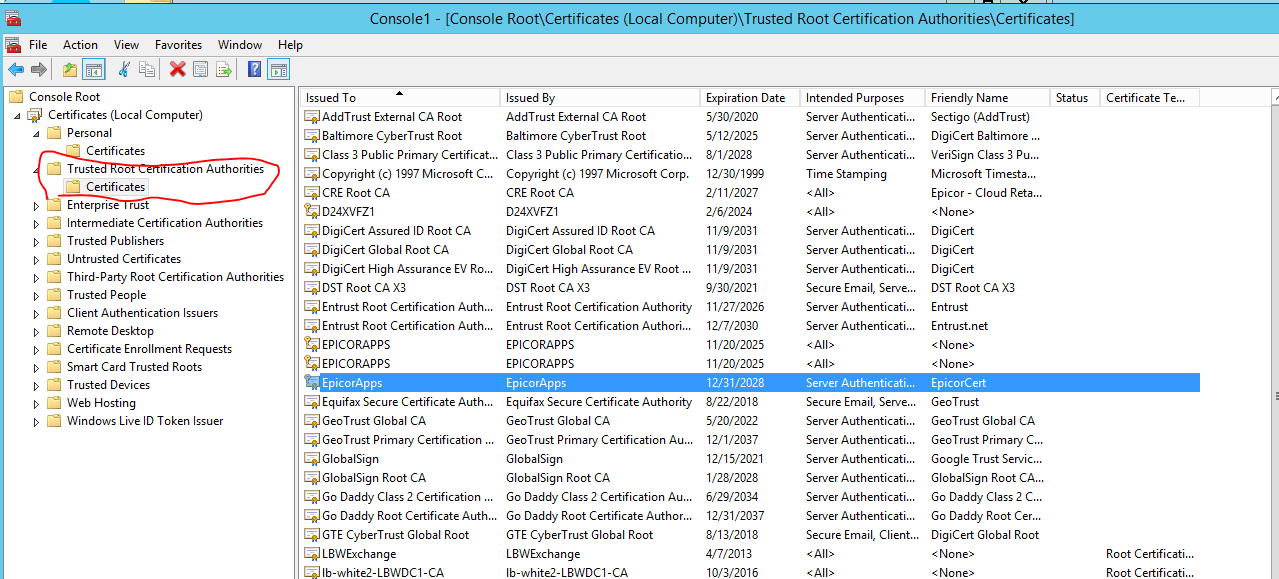
Looks like already found the bindings in IIS, but double check that the cert is in the trusted store.
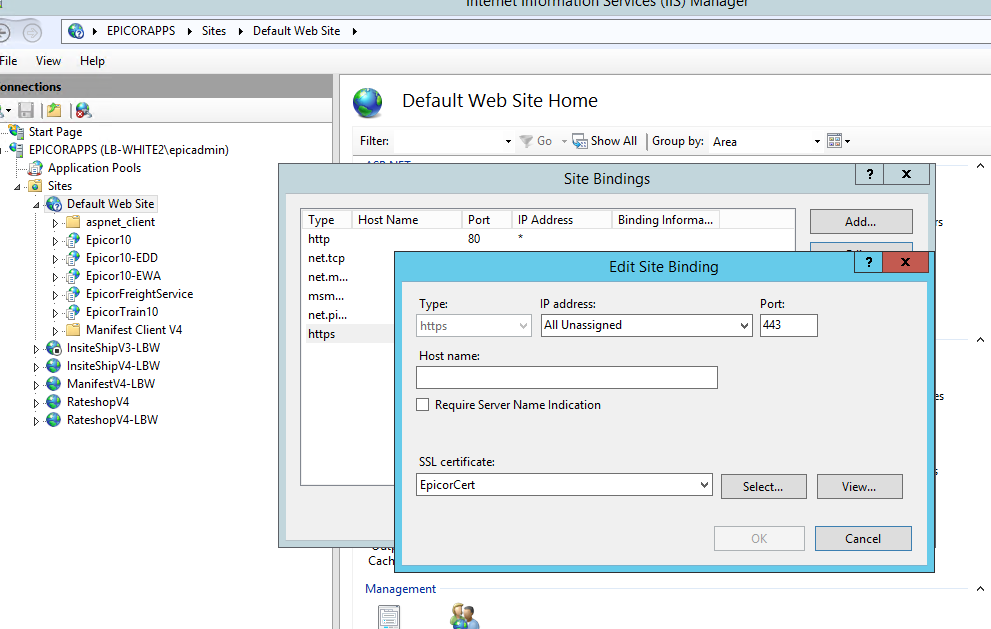
And that the the same cert is assigned in the binding.
When it’s running, can you navigate to the site through a browser?
https://servername/
Looks like already found the bindings in IIS, but double check that the cert is in the trusted store.
And that the the same cert is assigned in the binding.
When it’s running, can you navigate to the site through a browser?
https://servername/
I’m going to have to leave it for the day now, particularly as the immediate panic is passed without https there at all. But I would like to get to the bottom of the problem in due course.
The certificate is in that trusted store, but it’s also in Personal, and only the Personal options show up in “select” for bindings. And there’s an error navigating to the site: ERR_CERT_COMMON_NAME_INVALID, which looks like a clue.
Thanks to all for the help, by the way.
Update.
With @Hally’s suggestion to re-select the certificate, and @paulosborne’s guidance around the bindings, we found a way to a fix, though I’m still worried about how this happened and whether there’s a problem with the certificate set-up itself.
Our Endpoint Binding is UsernameWindowsChannel for net.tcp and None for both http and https. However, the problem was related to the https binding on Default Website in IIS (but it’s not clear what the problem was).
After deleting the https binding completely from Default Website in IIS, and recycling all the app pools including default, the Admin Console could connect to all our dev environments (unusually slowly, but OK). After adding the binding back with exactly the same settings as before it also continued to work, so something invisible to everywhere we were looking must have been altered or corrupted somehow. We are now back with exactly the same set-up as had been working yesterday morning and was not working through the rest of the day, and it is working.
Whew! Removing the cert and reapplying from scratch, I think would fix the binding issue. Before you do restart the server and see if things are broken again first.
Glad it got sorted out.
Following your advice I did do that, and unfortunately it didn’t solve the problem in this case.
But you get a lot of the credit for what did work - thanks - because removing the binding completely and adding it back feels like a more drastic version of the same approach and I wouldn’t have thought of it without your direction.
Epicor Support have just been back on and they’re as puzzled as anyone, incidentally. But at least we’re back up, and it’s a good thing we run our dev environments separately.
No argument there.
Take care.
Good news - regards the “unusually slowly” comment, that is kind of expected when the appserver first spins up. It does a lot of caching as services are called upon. Search the forum for a more detailed explanation from Bart Elia.
If you look in Task Manager on your server, when you’ve just done Recycle App Pool - watch IIS Worker Process, it will start off using very little RAM and then climb up. My observation is that EAC and the Epicor Client will become responsive when it reaches approx 1GB. Then, as the system is used it climbs - my production system is currently running at 4.5GB, but I do see this go higher to approx 6GB.